
Historia pewnej rekrutacji #
Jakiś czas temu zostałem zaproszony na proces rekrutacyjny na stanowisko SysAdmina przez pewną firmę i dostałem “pracę domową” składającą się z dwóch zadań mających sprawdzić moje praktyczne umiejętności i podejście do problemu. Firma okazała się turboniepoważna i mimo pozytywnego feedbacku od autora zadań kilka dni później, zasłaniając się “wewnętrznymi problemami” poprosiła mnie o chwilę cierpliwości. Kilkadziesiąt chwil później kontakt się urwał i po 3 tygodniach uznałem że czas o nich zapomnieć. Ale zadania zostały i warte są opublikowania. Nic nie wspomniano o zakazie publikacji rozwiązań, a teraz nie zamierzam o to pytać. Tak czy inaczej - jeśli dostaniecie od jakiejś firmy identyczne lub podobne zadania - uważajcie na nich.
Wstęp do zadań #
Zadania były dwa i podzielę je na dwa posty. Z drobnego lenistwa rozwiązania zostawię w oryginalnej formie i języku w którym je przesłałem (czyli angielskim).
Na sam początek kilka słów o środowisku testowym, systemie prezentacji wyników i założeniach. Dla niecierpliwych - ładne wykresy są na końcu 😉
System #
Hardware #
- VMware virtual machine hosted on Windows PC
- 16GB RAM
- 1x 8 core CPU (Intel Xeon E5540)
- System disk - virtual SCSI 20GB ext4
- hosted on LSI SAS card, RAID1, NTFS formatted 15k RPM hard drive
Software #
- OS - Ubuntu Server 18.04 LTS
- installed using standard wizard
- Database - PostgreSQL 10
Storage #
I decided to have one VM setup for both exercises so data disk is optimized for PostgreSQL database. Data disk (`/home`) is hosted on same physical matrix as system disk. Binaries and test reports stored on different disk than main IO operations not to affect baselines/performance.
Data visualization #
Methodology: #
- all scrips produce csv which is easily parsable by everything from awk, including quick Excel up to tools like R and plotly.js
- plotly.js was decided as it provides interactive graphs in html+js form which is easily available to display everywhere; it allows pretty advanced plotting and data import from various sources like CSV files
- I used it previously for big CSVs (20-30MB logs) without a problem on modern browsers.
Including JS code of each graph page in this document would be pointless but scaffold code is linked to show simplicity: https://codepen.io/plotly/pen/eNaErL
Basic concept of JS code #
- loadFile selects which data set to work on
- Plotly.d3.csv loads CSV over network to memory
- processData gets associative table, parses row by row and adds to new 1 dimensional tables and some additional computations like avg values are done
- Plotly.newPlot fills HTML div with data series and layout config
Methodology and tricks common for both tasks #
- `###` denotes some omitted lines from verbose commands
- `ntfy` which appears in long running tasks is alias using ntfy script that can send messages to different chat providers like slack or telegram; it’s quite useful to step away from terminal (in-browser notification) or computer (mobile phone notification)
- https://pypi.org/project/ntfy/
#
Zadanie 1 - disk baselines #
Pierwsze polegało na przeprowadzeniu testów obciążeniowych dysku i zebranie metryk wydajności w formie umożliwiającej łatwe zobrazowanie w formie wykresów.
Environment #
apt install bonnie++ sysstat
First iteration - iostat-csv + R/GSheet #
Data collection #
Simple wrapper from internet
root@sah:/home/sah# cd /var/sah/bin; git clone https://github.com/ymdysk/iostat-csv.git
root@sah:/home/sah#
Simple test - `bonnie++` simple test (2x RAM size) on data disk, simple wrapper over `iostat -x` that ouputs csv run in parallel.
terminal 1:
root@sah:/home/sah# time bonnie++ -d /home/sah/tests/ -r 16192 -u daniel
Using uid:1000, gid:1000.
Writing a byte at a time...done
Writing intelligently...done
Rewriting...done
Reading a byte at a time...done
Reading intelligently...done
start 'em...done...done...done...done...done...
Create files in sequential order...done.
Stat files in sequential order...done.
Delete files in sequential order...done.
Create files in random order...done.
Stat files in random order...done.
Delete files in random order...done.
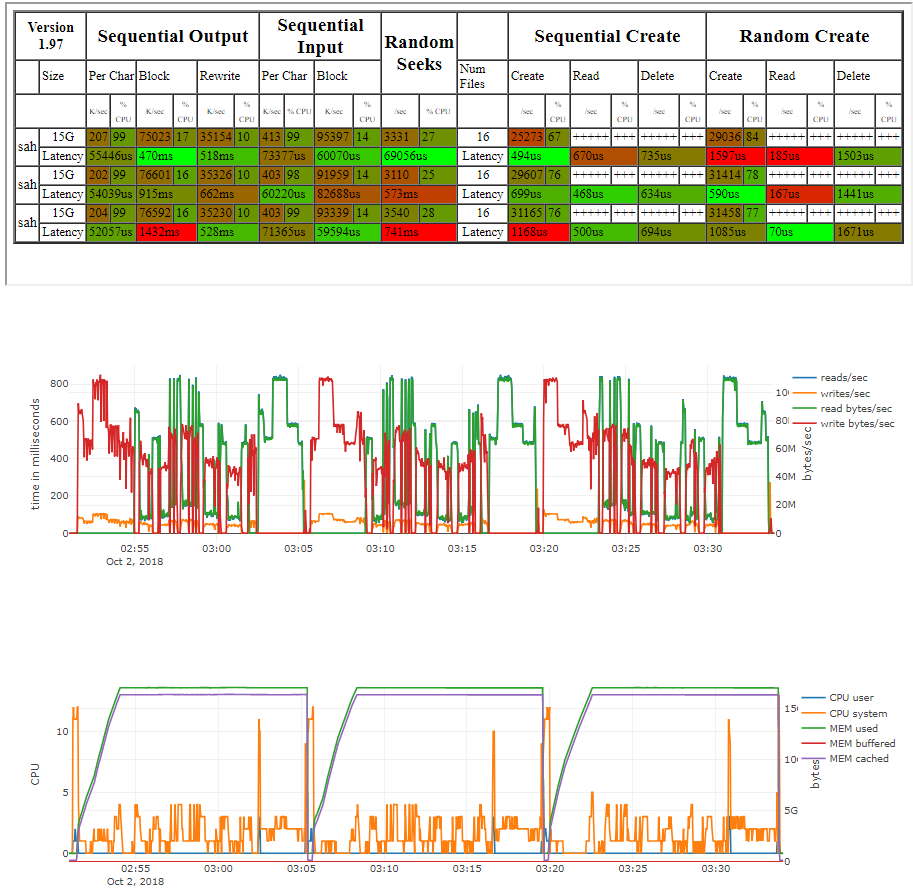
Version 1.97 ------Sequential Output------ --Sequential Input- --Random-
Concurrency 1 -Per Chr- --Block-- -Rewrite- -Per Chr- --Block-- --Seeks--
Machine Size K/sec %CP K/sec %CP K/sec %CP K/sec %CP K/sec %CP /sec %CP
sah 32G 203 99 28598 9 52906 14 441 99 156629 24 649.2 32
Latency 54332us 2904ms 302ms 31186us 78416us 209ms
Version 1.97 ------Sequential Create------ --------Random Create--------
sah -Create-- --Read--- -Delete-- -Create-- --Read--- -Delete--
files /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP
16 17954 47 +++++ +++ 27306 51 21447 54 +++++ +++ 27218 48
Latency 867us 680us 1587us 566us 112us 1260us
1.97,1.97,sah,1,1537736827,32G,,203,99,28598,9,52906,14,441,99,156629,24,649.2,32,16,,,,,17954,47,+++++,+++,27306,51,21447,54,+++++,+++,27218,48,54332us,2904ms,302ms,31186us,78416us,209ms,867us,680us,1587us,566us,112us,1260us
real 34m24.300s
user 0m10.288s
sys 4m34.876s
root@sah:/home/sah#
terminal 2:
root@sah:/home/daniel# /var/sah/bin/iostat-csv/iostat-csv.sh | tee -a /var/sah/task1_iter1.csv
Date,Time,%user,%nice,%system,%iowait,%steal,%idle,Device,r/s,w/s,rkB/s,wkB/s,rrqm/s,wrqm/s,%rrqm,%wrqm,r_await,w_await,aqu-sz,rareq-sz,wareq-sz,svctm,%util,Device,r/s,w/s,rkB/s,wkB/s,rrqm/s,wrqm/s,%rrqm,%wrqm,r_await,w_await,aqu-sz,rareq-sz,wareq-sz,svctm,%util,Device,r/s,w/s,rkB/s,wkB/s,rrqm/s,wrqm/s,%rrqm,%wrqm,r_await,w_await,aqu-sz,rareq-sz,wareq-sz,svctm,%util,Device,r/s,w/s,rkB/s,wkB/s,rrqm/s,wrqm/s,%rrqm,%wrqm,r_await,w_await,aqu-sz,rareq-sz,wareq-sz,svctm,%util
09/24/18,02:24:56,0.10,0.00,0.62,2.39,0.00,96.89,loop0,0.01,0.00,0.07,0.00,0.00,0.00,0.00,0.00,1.36,0.00,0.00,10.79,0.00,0.11,0.00,loop1,0.00,0.00,0.02,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,6.60,0.00,0.00,0.00,sda,1.18,1.03,34.43,32.15,0.09,2.44,7.07,70.40,15.24,181.59,0.20,29.16,31.35,8.08,1.78,sdb,31.94,4.30,4067.23,4259.74,0.11,0.70,0.34,14.02,2.39,3352.68,14.48,127.34,990.63,3.65,13.23
09/24/18,02:24:57,0.00,0.00,0.00,0.00,0.00,100.00,loop0,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,loop1,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,sda,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,sdb,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00
###...
Data parsing
root@sah:/var/sah# tail -n2300 task1_iter1.csv > task1_iter1_stripped.csv
root@sah:/var/sah# cat task1_iter1.csv | head -n1 | tr ',' '\n' | cat -n
## column numbers for awk
root@sah:/var/sah# cat task1_iter1.csv | head -n 2300 | awk 'BEGIN {FS=",";OFS=","}{print $1,$2,$3,$5,$58,$59,$60,$61,$66,$67,$68}' > task1_iter1_stripped.csv
Date,Time,%user,%system,r/s,w/s,rkB/s,wkB/s,r_await,w_await,aqu-sz
09/24/18,02:24:56,0.10,0.62,31.94,4.30,4067.23,4259.74,2.39,3352.68,14.48
09/24/18,02:24:57,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00
09/24/18,02:24:58,0.75,8.51,0.00,0.00,0.00,0.00,0.00,0.00,0.00
09/24/18,02:24:59,1.62,11.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00
09/24/18,02:25:00,1.25,11.25,0.00,0.00,0.00,0.00,0.00,0.00,0.00
09/24/18,02:25:01,1.12,11.49,0.00,0.00,0.00,0.00,0.00,0.00,0.00
09/24/18,02:25:02,1.25,11.61,0.00,0.00,0.00,0.00,0.00,0.00,0.00
09/24/18,02:25:03,1.25,11.25,0.00,1.98,0.00,23.76,0.00,8.00,0.02
09/24/18,02:25:04,1.25,11.36,0.00,0.00,0.00,0.00,0.00,0.00,0.00
root@sah:/var/sah# head task1_iter1_stripped.csv
Date,Time,%user,%system,r/s,w/s,rkB/s,wkB/s,r_await,w_await,aqu-sz
09/24/18,02:24:56,0.10,0.62,31.94,4.30,4067.23,4259.74,2.39,3352.68,14.48
09/24/18,02:24:57,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00
09/24/18,02:24:58,0.75,8.51,0.00,0.00,0.00,0.00,0.00,0.00,0.00
09/24/18,02:24:59,1.62,11.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00
09/24/18,02:25:00,1.25,11.25,0.00,0.00,0.00,0.00,0.00,0.00,0.00
09/24/18,02:25:01,1.12,11.49,0.00,0.00,0.00,0.00,0.00,0.00,0.00
09/24/18,02:25:02,1.25,11.61,0.00,0.00,0.00,0.00,0.00,0.00,0.00
09/24/18,02:25:03,1.25,11.25,0.00,1.98,0.00,23.76,0.00,8.00,0.02
09/24/18,02:25:04,1.25,11.36,0.00,0.00,0.00,0.00,0.00,0.00,0.00
root@sah:/var/sah#
Data visualization #
First iteration in R
#!/usr/bin/env Rscript
library(lattice)
d = read.csv("d:/sah/task1_iter1_stripped.csv", header = TRUE)
# crude all-in-one
f <- paste(paste(names(d[,-1,drop=FALSE]), collapse="+"), names(d[,2,drop=FALSE]), sep=" ~ ")
xyplot(as.formula(f), data=d, type='l', auto.key=list(space='right'))
R is not suitable for interactive analysis or any easy analysis at all with huge datasets that need every point to be shown.
Second iteration in GSheet, kind of disappointing - https://docs.google.com/spreadsheets/d/13QFwxlwpk5QKAj-fj3VX_o49nSNUIYdHEL54ijR_DiQ/edit?usp=sharing
Second iteration - custom watcher script and plotly.js #
Custom script `statsWatcher.sh` #
#!/bin/bash
dev=$1
out=$2
if [[ -z $dev || -z $out ]]; then
echo "usage: $0 diskToMonitor outputLogFilename"
exit 1
fi
echo "timestamp,mem_free,mem_buff,mem_cache,cpu_user,cpu_sys,cpu_iowait,r_s,w_s,rkB_s,wkB_s,r_await,w_await,avg_q,util_perc" >> $out
while [[ true ]]; do
date=`date +%s`
diskStats=`iostat -t -x $dev -y 1 1 | tail -n 2| head -n1 | awk '{print $2","$3","$4","$5","$10","$11","$12","$16}'`
#r/s,w/s,rkB/s,wkB/s,r_await,w_await,aqu-sz,%util
sysStats=`vmstat -w 1 2 | tail -n1 | awk '{print $4","$5","$6","$13","$14","$16}'`
#mem_free,mem_buff,mem_cache,cpu_user,cpu_sys,cpu_iowait
echo $date","$sysStats","$diskStats >> $out
#sleep 1
done
`sleep 1` is commented out since `iostat` and `vmstat` need to run for one second to collect current statistics. First output line is average value from boot time until now so it’s not valuable.
Simple test benchmark #
Simple test was performed to see how data is displayed on graphs. It consisted of following commands executed on another machine:
thor:/# dd if=/dev/urandom of=/home/xxxx bs=1M count=1k
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 8.30361 s, 129 MB/s
thor:/# dd if=/dev/urandom of=/home/xxxx bs=1M count=100k
^C7253+0 records in
7252+0 records out
7604273152 bytes (7.6 GB, 7.1 GiB) copied, 69.5066 s, 109 MB/s
thor:/# dd of=/dev/urandom if=/home/xxxx bs=1M count=100k
7252+0 records in
7252+0 records out
7604273152 bytes (7.6 GB, 7.1 GiB) copied, 59.418 s, 128 MB/s
thor:/# dd of=/home/xxxx2 if=/home/xxxx bs=1M count=100k
7252+0 records in
7252+0 records out
7604273152 bytes (7.6 GB, 7.1 GiB) copied, 59.418 s, 128 MB/s
thor:/# dd of=/home/xxxx2 if=/home/xxxx bs=1M count=100k
7252+0 records in
7252+0 records out
7604273152 bytes (7.6 GB, 7.1 GiB) copied, 147.806 s, 51.4 MB/s
thor:/# rm /home/xxxx2 /home/xxxx
thor:/#
Result of running `./statsWatcher.sh /dev/sdb testLog.csv` (first 20 lines):
timestamp,mem_free,mem_buff,mem_cache,cpu_user,cpu_sys,cpu_iowait,r_s,w_s,rkB_s,wkB_s,r_await,w_await,avg_q,util_perc
1538404489,9254124,206608,1590424,0,0,0,0.00,1.00,0.00,0.50,0.00,4.00,0.00,0.40
1538404491,9257000,206608,1590452,0,0,0,0.00,52.00,0.00,712.50,0.00,2.08,0.14,14.00
1538404493,9256604,206608,1590452,0,0,0,0.00,15.00,0.00,57.00,0.00,2.93,0.04,2.00
1538404495,9256812,206608,1590452,0,0,0,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00
1538404497,9256788,206608,1590452,0,0,0,0.00,48.00,0.00,629.00,0.00,3.50,0.17,16.00
1538404499,9256812,206608,1590452,0,0,0,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00
1538404501,9256004,206608,1590452,0,0,0,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00
1538404503,9256948,206608,1590424,0,0,0,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00
1538404505,9257516,206608,1590424,0,0,0,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00
1538404507,9257104,206608,1590424,0,0,0,0.00,51.00,0.00,645.00,0.00,3.45,0.18,17.20
1538404509,9257252,206608,1590424,0,0,0,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00
1538404511,9257352,206608,1590448,0,0,0,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00
1538404513,9257428,206608,1590448,0,0,0,0.00,4.00,0.00,9.00,0.00,9.00,0.04,3.60
1538404515,9257396,206608,1590448,0,0,0,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00
1538404517,9263560,206608,1590444,0,0,0,0.00,49.00,0.00,637.00,0.00,3.67,0.18,17.60
1538404519,9263400,206608,1590444,0,0,0,0.00,3.00,0.00,5.00,0.00,12.00,0.04,3.60
1538404521,9264192,206608,1590420,0,0,0,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00
1538404523,9264472,206608,1590416,0,0,0,0.00,3.00,0.00,5.00,0.00,9.33,0.03,2.80
1538404525,9265104,206608,1590416,0,0,0,0.00,0.00,0.00,0.00,0.00,0.00,0.00,0.00
Graphs #
Plotly.js was described in intro. Graphs created with final version of plotly html template: https://storage.dsinf.net/sah/task1_benchmarks/baselines.html#testLog
Real baselines #
Target disk #
I decided to add third virtual disk that can be moved to different physical disk on my workstation and reformat it at ease (`/home` has postgresql for task2).
Here’s setup of it under VMware:
- virtual SCSI connected
- independent (not affected by snapshots), persistent
- 16GB (same as RAM)
- preallocated
- stored as single file on host filesystem
- first stored on same disk as rootfs and `/home` (SAS 15k RPM HDD)
Test suite #
It’ll run baselines collector for 15 seconds without load, then perform 3 tests of bonnie++ (-x3 on 15G output data sizew) and again collect 15 minutes of idle stats. 3 files are created - bonnie.csv with raw results, bonnie.html with html formatted data and baseline.csv with IO and CPU stats.
logname=filesystem_ext4journal;
./statsWatcher.sh /dev/sdc $logname.baseline.csv & sleep 15; bonnie++ -u root -d /test/ -s15G -r7.5G -x3 -q > $logname.bonnie.csv; sleep 15; kill -9 `jobs -p`; bon_csv2html $logname.bonnie.csv > $logname.bonnie.html
Testing various filesystems #
I’ve chosen same filesystems as in Task2 for database storage selection.
ext4 journalled
root@sah:/# mkfs.ext4 /dev/sdc1
mke2fs 1.44.1 (24-Mar-2018)
Creating filesystem with 4194048 4k blocks and 1048576 inodes
Filesystem UUID: 68d9ad29-e5ad-4040-b5a8-648b3d686da5
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
root@sah:/# mount /dev/sdc1 /test/
root@sah:/#
root@sah:~/task1# logname=filesystem_ext4journal; ./statsWatcher.sh /dev/sdc $logname.baseline.csv & sleep 15; bonnie++ -u root -d /test/ -s15G -r7.5G -x3 -q > $logname.bonnie.csv; sleep 15; kill -9 `jobs -p`; bon_csv2html $logname.bonnie.csv > $logname.bonnie.html
[1] 9200
[1]+ Killed ./statsWatcher.sh /dev/sdc $logname.baseline.csv
root@sah:~/task1#
ext4 no journall
root@sah:~/task1# mkfs.ext4 -O ^has_journal /dev/sdc1
mke2fs 1.44.1 (24-Mar-2018)
/dev/sdc1 contains a ext4 file system
last mounted on /test on Mon Oct 1 16:14:47 2018
Proceed anyway? (y,N) y
Creating filesystem with 4194048 4k blocks and 1048576 inodes
Filesystem UUID: d9c66b94-4464-40cd-bc6d-5f6758bed555
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000
Allocating group tables: done
Writing inode tables: done
Writing superblocks and filesystem accounting information: done
root@sah:~/task1# mount /dev/sdc1 /test
root@sah:~/task1# logname=filesystem_ext4nojournal; ./statsWatcher.sh /dev/sdc $logname.baseline.csv & sleep 15; bonnie++ -u root -d /test/ -s15G -r7.5G -x3 -q > $logname.bonnie.csv; sleep 15; kill -9 `jobs -p`; bon_csv2html $logname.bonnie.csv > $logname.bonnie.html
[1] 15939
[1]+ Killed ./statsWatcher.sh /dev/sdc $logname.baseline.csv
root@sah:~/task1#
JFS
root@sah:~/task1# umount /test/
root@sah:~/task1# mkfs.jfs /dev/sdc1
mkfs.jfs version 1.1.15, 04-Mar-2011
Warning! All data on device /dev/sdc1 will be lost!
Continue? (Y/N) y
\
Format completed successfully.
16776192 kilobytes total disk space.
root@sah:~/task1# mount /dev/sdc1 /test/
root@sah:~/task1# logname=filesystem_jfs; ./statsWatcher.sh /dev/sdc $logname.baseline.csv & sleep 15; bonnie++ -u root -d /test/ -s15G -r7.5G -x3 -q > $logname.bonnie.csv; sleep 15; kill -9 `jobs -p`; bon_csv2html $logname.bonnie.csv > $logname.bonnie.html
[1] 22842
[1]+ Killed ./statsWatcher.sh /dev/sdc $logname.baseline.csv
root@sah:~/task1#
XFS
root@sah:~/task1# umount /test/
root@sah:~/task1# mkfs.xfs /dev/sdc1
mkfs.xfs: /dev/sdc1 appears to contain an existing filesystem (jfs).
mkfs.xfs: Use the -f option to force overwrite.
root@sah:~/task1# mkfs.xfs -f /dev/sdc1
meta-data=/dev/sdc1 isize=512 agcount=4, agsize=1048512 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=0, rmapbt=0, reflink=0
data = bsize=4096 blocks=4194048, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
root@sah:~/task1# mount /dev/sdc1 /test/
root@sah:~/task1# logname=filesystem_xfs; ./statsWatcher.sh /dev/sdc $logname.baseline.csv & sleep 15; bonnie++ -u root -d /test/ -s15G -r7.5G -x3 -q > $logname.bonnie.csv; sleep 15; kill -9 `jobs -p`; bon_csv2html $logname.bonnie.csv > $logname.bonnie.html
[1] 30026
[1]+ Killed ./statsWatcher.sh /dev/sdc $logname.baseline.csv
root@sah:~/task1#
Testing various physical disks #
The same ext4 formatted disk will be moved between following disks:
cheetah
- SAS connected 15k RPM HDD in hardware RAID1
- same as
/home - results stored in
physical_cheetah
SSD
- SATA2 connected modern SSD drive in software RAID1
- host OS disk
- results stored in `physical_ssd`
HDD
- SATA2 connected enterprise grade HDD WD Black disk
- results stored in
physical_hdd
Testing various block sizes on ext4 #
Those are only valid block sizes for ext4
1024
root@sah:~/task1# umount /test/
root@sah:~/task1# mkfs.ext4 -b 1024 /dev/sdc1
mke2fs 1.44.1 (24-Mar-2018)
/dev/sdc1 contains a ext4 file system
last mounted on /test on Mon Oct 1 21:20:22 2018
Proceed anyway? (y,N) y
Creating filesystem with 16776192 1k blocks and 1048576 inodes
Filesystem UUID: aebf6ae7-2b1b-4918-bd54-41ded0ee9028
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729, 204801, 221185, 401409, 663553,
1024001, 1990657, 2809857, 5120001, 5971969
Allocating group tables: done
Writing inode tables: done
Creating journal (65536 blocks): done
Writing superblocks and filesystem accounting information: done
root@sah:~/task1# mount /dev/sdc1 /test
root@sah:~/task1# logname=ext4blocksize1024; ./statsWatcher.sh /dev/sdc $logname.baseline.csv & sleep 15; bonnie++ -u root -d /test/ -s15G -r7.5G -x3 -q > $logname.bonnie.csv; sleep 15; kill -9 `jobs -p`; bon_csv2html $logname.bonnie.csv > $logname.bonnie.html
[1] 51212
[1]+ Killed ./statsWatcher.sh /dev/sdc $logname.baseline.csv
root@sah:~/task1#
2048
root@sah:~/task1# umount /test/
root@sah:~/task1# mkfs.ext4 -b 2048 /dev/sdc1
mke2fs 1.44.1 (24-Mar-2018)
/dev/sdc1 contains a ext4 file system
last mounted on /test on Mon Oct 1 20:50:58 2018
Proceed anyway? (y,N) y
Creating filesystem with 8388096 2k blocks and 1048576 inodes
Filesystem UUID: 1cd1df52-8d8b-4f92-8540-258ae88fc847
Superblock backups stored on blocks:
16384, 49152, 81920, 114688, 147456, 409600, 442368, 802816, 1327104,
2048000, 3981312, 5619712
Allocating group tables: done
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
root@sah:~/task1# mount /dev/sdc1 /test
root@sah:~/task1# logname=ext4blocksize2048; ./statsWatcher.sh /dev/sdc $logname.baseline.csv & sleep 15; bonnie++ -u root -d /test/ -s15G -r7.5G -x3 -q > $logname.bonnie.csv; sleep 15; kill -9 `jobs -p`; bon_csv2html $logname.bonnie.csv > $logname.bonnie.html
[1] 44356
[1]+ Killed ./statsWatcher.sh /dev/sdc $logname.baseline.csv
root@sah:~/task1#
4096
root@sah:~/task1# tune2fs -l /dev/sdc1 | grep -i block\ size
Block size: 4096
root@sah:~/task1# cp filesystem_ext4journal.baseline.csv ext4blocksize4096.baseline.csv
root@sah:~/task1# cp filesystem_ext4journal.bonnie.csv ext4blocksize4096.bonnie.csv
root@sah:~/task1# cp filesystem_ext4journal.bonnie.html ext4blocksize4096.bonnie.html
8192
root@sah:~/task1# umount /test/
root@sah:~/task1# mkfs.ext4 -b 8129 /dev/sdc1
Warning: blocksize 8129 not usable on most systems.
mke2fs 1.44.1 (24-Mar-2018)
/dev/sdc1 contains a ext4 file system
last mounted on Mon Oct 1 20:26:17 2018
Proceed anyway? (y,N) y
Creating filesystem with 4194048 4k blocks and 1048576 inodes
Filesystem UUID: 90417a62-0277-4cc8-92b5-4ac9efdaef49
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
root@sah:~/task1# mount /dev/sdc1 /test/
root@sah:~/task1# logname=ext4blocksize8192; ./statsWatcher.sh /dev/sdc $logname.baseline.csv & sleep 15; bonnie++ -u root -d /test/ -s15G -r7.5G -x3 -q > $logname.bonnie.csv; sleep 15; kill -9 `jobs -p`; bon_csv2html $logname.bonnie.csv > $logname.bonnie.html
[1] 37635
[1]+ Killed ./statsWatcher.sh /dev/sdc $logname.baseline.csv
root@sah:~/task1#
Testing various thread count #
Tested 2 threads of bonnie++
root@sah:~/task1# logname=threads_2; ./statsWatcher.sh /dev/sdc $logname.baseline.csv & sleep 15; bonnie++ -u root -d /test/ -s7G -r3.5G -x3 -q > $logname.1.bonnie.csv & bonnie++ -u root -d /test/ -s7G -r3.5G -x3 -q > $logname.2.bonnie.csv; sleep 1m; kill -9 `jobs -p`; bon_csv2html $logname.1.bonnie.csv > $logname.bonnie.html; bon_csv2html $logname.2.bonnie.csv >> $logname.bonnie.html
[1] 90591
[2] 90669
[2]+ Done bonnie++ -u root -d /test/ -s7G -r3.5G -x3 -q > $logname.1.bonnie.csv
[1]+ Killed ./statsWatcher.sh /dev/sdc $logname.baseline.csv
root@sah:~/task1#
Baselines of ETL (task2) #
5 tests were performed for baselining purposes:
data download & unpacking it - etl_dataload
root@sah:/home/csv# ./statsWatcher.sh /dev/sdb etl_dataload.csv & sleep 15; for i in `seq -f "%05g" 0 29`; do wget https://XXXXXXXX.s3.amazonaws.com/hive_csv_altus_gz/part-$i.gz; done; sleep 30; for i in `seq -f "%05g" 0 29`; do gzip -d part-$i.gz; done; sleep 15; kill -9 `jobs -p`; ntfy -b telegram send "done"
[1] 97612
[1]+ Killed ./statsWatcher.sh /dev/sdb etl_dataload.csv
root@sah:/home/csv#
1.2GB chunks with 1 threads - etl_1_1
root@sah:/home/csv# timepse "truncate table extract"
TRUNCATE TABLE
4.88
root@sah:/home/csv# logname=etl_1_1; ./statsWatcher.sh /dev/sdb $logname.baseline.csv & sleep 15; ./multipleFilesLoader 1 $logname.log.csv; sleep 15; kill -9 `jobs -p`
[2] 126089
[1]- Killed ./statsWatcher.sh /dev/sdc $logname.baseline.csv
[2]+ Killed ./statsWatcher.sh /dev/sdb $logname.baseline.csv
root@sah:/home/csv#
1.2GB chunks with 4 threads- etl_1_4
root@sah:/home/csv# timepse "truncate table extract"
TRUNCATE TABLE
3.12
root@sah:/home/csv# logname=etl_1_4; ./statsWatcher.sh /dev/sdb $logname.baseline.csv & sleep 15; ./multipleFilesLoader 4 $logname.log.csv; sleep 15; kill -9 `jobs -p`
[2] 17749
[1]- Killed ./statsWatcher.sh /dev/sdb $logname.baseline.csv
[2]+ Killed ./statsWatcher.sh /dev/sdb $logname.baseline.csv
root@sah:/home/csv#
2.4GB chunks with 8 threads - etl_2_8
root@sah:/home/csv# ls -alh part-*
-rw-r--r-- 1 root root 2.4G Oct 2 18:28 part-0_2
-rw-r--r-- 1 root root 2.4G Oct 2 18:32 part-10_2
-rw-r--r-- 1 root root 2.4G Oct 2 18:32 part-12_2
-rw-r--r-- 1 root root 2.4G Oct 2 18:33 part-14_2
-rw-r--r-- 1 root root 2.4G Oct 2 18:34 part-16_2
-rw-r--r-- 1 root root 2.4G Oct 2 18:34 part-18_2
-rw-r--r-- 1 root root 2.4G Oct 2 18:35 part-20_2
-rw-r--r-- 1 root root 2.4G Oct 2 18:29 part-2_2
-rw-r--r-- 1 root root 2.4G Oct 2 18:36 part-22_2
-rw-r--r-- 1 root root 2.4G Oct 2 18:36 part-24_2
-rw-r--r-- 1 root root 2.4G Oct 2 18:37 part-26_2
-rw-r--r-- 1 root root 2.4G Oct 2 18:38 part-28_2
-rw-r--r-- 1 root root 2.4G Oct 2 18:30 part-4_2
-rw-r--r-- 1 root root 2.4G Oct 2 18:30 part-6_2
-rw-r--r-- 1 root root 2.4G Oct 2 18:31 part-8_2
root@sah:/home/csv# timepse "truncate table extract"
TRUNCATE TABLE
1.25
root@sah:/home/csv# logname=etl_2_8; ./statsWatcher.sh /dev/sdb $logname.baseline.csv & sleep 15; ./multipleFilesLoader 4 $logname.log.csv; sleep 15; kill -9 `jobs -p`
[1] 39851
[1]+ Killed ./statsWatcher.sh /dev/sdb $logname.baseline.csv
root@sah:/home/csv#
pg_bulkload parallel - etl_pgbulkload
root@sah:/home/csv# timepse "truncate table extract"
TRUNCATE TABLE
1.21
root@sah:/home/csv# logname=etl_pgbulkload; ./statsWatcher.sh /dev/sdb $logname.baseline.csv & sleep 15; for f in part-*; do /home/pg_bulkload/bin/pg_bulkload -d sah -o
As with bonnie++ they were run with 15 seconds overlap of idle state.
Results #
- baselines and binaries: sah_task1_benchmarks.zip
DELIMITER=\t' -i $f import_alldata.ctl; done; sleep 15; kill -9 `jobs -p`
[1] 50658
[1]+ Killed ./statsWatcher.sh /dev/sdb $logname.baseline.csv
root@sah:/home/csv#