
Szukając systemu do tworzenia kopii zapasowej, który będzie działał zarówno na boxach na labowym serwerze, jak i na stacjach roboczych z Linuksem, Windowsem i macOS kilka lat temu zatrzymałem się na rozwiązaniu UrBackup, które opisałem tutaj. Skusiła mnie głównie funkcjonalność backupowania nie tylko plików, lecz i obrazów dysków twardych. Okazało się jednak, że działa ona głównie na Windowsie przez VSS (Volume Shadow Copy), a na Linuksach wymaga zewnętrznych skryptów, które zrobią migawkę systemu plików mniej, lub bardziej inteligentnie (np. za pomocą datto). Przez serię problemów z triggerowaniem zadań z serwera (głównie na stacjach roboczych, które nie są online 24/7) i przechodzeniem agentów w stan nieoperacyjny postanowiłem szukać dalej. Tym sposobem doszedłem do Duplicati i monitorowaniu go za pomocą Prometheusa.
Kilka słów o Duplicati #
Duplicati przyciąga uwagę architekturą nieposiadającą serwera - klienci posiadają zestaw narzędzi do wykonania backupu oraz opcjonalny scheduler i webowy interfejs konfiguracyjny. Te dwa ostatnie są przeznaczone dla stacji roboczych i statycznych serwerów (czyli raczej nie będą to kontenery). Backup wysyłany jest do storage providera - może nim być lokalny folder, serwer FTP, Amazon S3, Dropbox i cała masa innych.
Poza tym całość jest zaprojektowana tak, aby można było backup odtworzyć ręcznie - używane są standardowe narzędzia takie jak zip i tar. Do szyfrowania używany jest AES256 lub PGP. Przenośność między platformami zapewnia .NET framework - oznacza to pewien narzut związany z instalacją środowiska mono na Linuksach, ale zapewnia elastyczność.
Instalacja na desktopie jest śmiesznie łatwa, a konfiguracja w web-ui polega na odpowiedzi na serię pytań w wizardzie. Jest to pozytywna odmiana po narzędziach w rodzaju Bacula. Moim zdaniem użytkownicy współczesnego Linuksa zasługują na łatwe w obsłudze narzędzia.
Instalacja i podstawu używania #
Jak się ma sprawa na linuksowych boxach, które nie powinny wystawiać interfejsu konfiguracyjnego? Podejść jest kilka, ale ja opiszę wykorzystanie crona do triggerowania zadań oraz Prometheusa do monitorowania ich postępu.
Pierwszym krokiem jest instalacja - strona https://www.duplicati.com/download zawiera paczki dla Windowsa (msi), deb i rpm dla Linuksów oraz zipa z samymi plikami wykonywalnymi .net. deb i rpm są bezarchitekturowe - mają dependencje na środowisko mono i to, co znajduje się w archiwum zip - binarki. Oznacza to, że bez problemu odpalą się na RaspberryPi używającym procesora ARM.
duplicati-cli to narzędzie do wykonywania zadań, nas oczywiście na tym etapie najbardziej interesuje backup
duplicati-cli:
See duplicati.commandline.exe help topic for more information.
General: example, changelog
Commands: backup, find, restore, delete, compact, test, compare, purge, vacuum
Repair: repair, affected, list-broken-files, purge-broken-files
Debug: debug, logging, create-report, test-filters, system-info, send-mail
Targets: rclone, ftp, msgroup, onedrivev2, sharepoint, googledrive, gcs, cloudfiles, mega, s3, ssh, jottacloud, webdav, hubic, tahoe, b2, aftp, azure, file, od4b, mssp, openstack, box, sia, dropbox
Modules: aes, gpg, zip, 7z, console-password-input, mssql-options, hyperv-options, http-options, sendhttp, sendmail, runscript, sendxmpp, check-mono-ssl
Formats: date, time, size, encryption, compression
Advanced: mail, advanced, returncodes, filter, filter-groups, option
Wrapper i dygresja o autoryzacji do storage backendów #
Jeśli zamierzamy wykorzystać duplicati-cli w więcej niż jednym miejscu warto pokusić się o napisanie drobnego wrappera. Mój dostosowany jest do wysyłania danych na dropboxa, więc jednym z parametrów jest auth_id - token aplikacji.
Warto w tym miejscu zrobić dygresję - Duplicati ogarnia to, co jest największą bolączką tego typu rozwiązań, które integrują się z dostawcami powierzchni dyskowej jak OneDrive, czy Dropbox. Twórcy hostują serwer (rozwiązanie opensource, które można postawić samodzelnie jeśli im nie ufamy) służący do pobierania tokenów od providerów. Dostęp do niego jest wbudowany w web-ui, można też osiągnąć go spoza aplikacji, co przydatne jest do instalacji na serwerach. Można go znaleźć na https://duplicati-oauth-handler.appspot.com/
Poza auth_id lub generalnie jakąś formą adresu naszego storage backendu warto sparametryzować ścieżkę, którą backupujemy oraz hasło szyfrujące pliki i politykę retencji.
Mając na uwadze powyższe zapisy można pokusić się o napisanie takiego, oto skryptu:
#!/bin/bash
path=$1
authid=$2
passphrase=$3
retention=$4
path_encoded="`echo ${path} | base32 | tr '=' '_'`"
hostname="`hostname`"
START="$(date +%s)"
EXITCODE=1
for i in `seq 10`
do
/usr/bin/duplicati-cli backup "dropbox:///PREFIX/${hostname}${path}?authid=${authid}" "${path}" --backup-name="${path}" --dbpath="/var/duplicati_${path_encoded}.sqlite" --encryption-module=aes --compression-module=zip --dblock-size=50mb --passphrase="${passphrase}" --retention-policy="${retention}" --disable-module=console-password-input
EXITCODE=$?
if [ $EXITCODE -lt 10 ]
then
break
fi
sleep $((1 + RANDOM % 60))
done
END="$(date +%s)"
Dzieje się w nim kilka nie do końca intuicyjnych rzeczy, czas więc na wyjaśnienia.
Pierwsza sprawa to docelowa lokalizacja backupów: umieszczane są tak jak typowe dane zewnętrznej aplikacji dropboksowej w folderze Applications na Dropboxie w podfolderze Duplicati backups - warto więc od razu usunąć go z synchronizacji na desktopie - no chyba że mamy dużo miejsca na dysku 🙂
Dalsze elementy ścieżki to prefiks (na screenshocie poniżej jest to amaterasu - tak nazywa się mój serwer), nazwa hosta wyciągana dynamicznie przez skrypt, oraz pełna ścieżka do backupowanego foldero - bardzo ułatwia to lokalizację konkretnych danych.
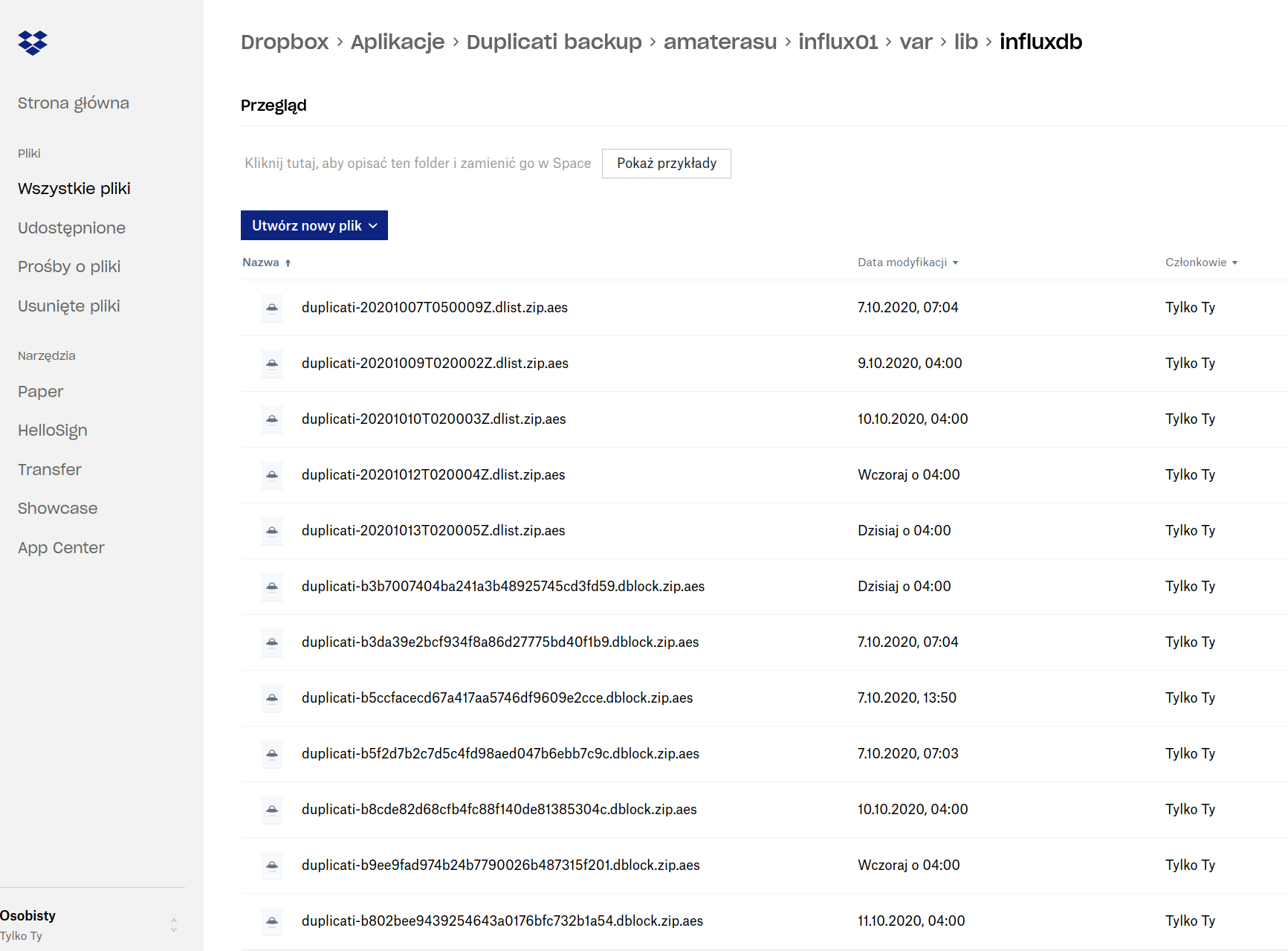
Kolejny element to dbpath, który odpowiada za lokalną bazę danych pomagającą Duplicati utrzymać stan plików. Bashowy potworek echo ${path} | base32 | tr '=' '_', który tworzy jego wartość enkoduje ścieżkę tak by mogła być nazwą pliku bazy SQLite. Nie może to być stała wartość, gdyż wtedy nie można by uruchomić dwóch różnych procesów backupowania na jednym hoście. Natomiast odwracalne base32 z podmianą znaku równości (który sprawia kłopot w niektórych miejscach w bashu) ma tę przewagę nad funkcją skrótu w rodzaju MD5, że późniejsze debugowanie sytuacji w rodzaju przepełniającej się bazy danych jest łatwiejsze.
Retention policy określa, ile backupów z danego okresu ma być przechowywane. Moja domyślna wartość to "1W:1D,4W:1W,12M:1M". Poniżej wklejam to, co można znaleźć w helpie duplicati-cli, ale generalnie dość pomocne jest web-ui zawierające kilka często używanych wartości.
duplicati-cli help retention-policy:
-retention-policy (String): Reduce number of versions by deleting old intermediate backups
Use this option to reduce the number of versions that are kept with increasing version age by deleting most of the old backups. The expected format is a comma separated list of colon separated time frame and interval pairs. For example the value "7D:0s,3M:1D,10Y:2M" means "For 7 day keep all backups, for 3 months keep one backup every day, for 10 years one backup every 2nd month and delete every backup older than this.". This option also supports using the specifier "U" to indicate an unlimited time interval.
Całe wywołanie duplicati-cli w moim wrapperze opakowane jest pętlą próbującą wykonać backup 10 razy, a po każdym niepowodzeniu czekając losową liczbę sekund od 1 do 60 (linijka ze sleep). Istotną pułapką jest tutaj exitcode - duplicati-cli nie do końca przestrzega standardu POSIX i nie zawsze kod wyjścia różny od zera oznacz błąd - stąd [ $EXITCODE -lt 10 ] w ifie, który sprawdza, czy można opuścić pętlę for po udanym backupie.
duplicati-cli help returncodes:
Duplicati reports the following return/exit codes:
0 - Success
1 - Successful operation, but no files were changed
2 - Successful operation, but with warnings
50 - Backup uploaded some files, but did not finish
100 - An error occurred
200 - Invalid commandline arguments found
Monitorowanie za pomocą Prometheusa #
Idąc za regułą Torvaldsa talk is cheap - show me the code! znowu zacznę od kawałka skryptu, który potem wyjaśnię 🙂
Pierwszym elementem jest lekka modyfikcja wrappera z poprzedniej sekcji tak, by zapisywał metryki.
# put this before $START variable declaration
metrics_name="duplicati_${hostname}_`echo $path | tr '/' '_'`"
metrics_dir="/var/lib/prometheus/node-exporter/"
mkdir -p $metrics_dir
chown prometheus $metrics_dir
# put this at the end of script - after $END variable
cat << EOF > "$metrics_dir/${metrics_name}.prom.$$"
${metrics_name}_last_run_start $START
${metrics_name}_last_run_seconds $(($END - $START))
${metrics_name}_last_exitcode $EXITCODE
EOF
mv "$metrics_dir/${metrics_name}.prom.$$" "$metrics_dir/${metrics_name}.prom"
Dlaczego najpierw zapisuję tekst do pliku z nazwą kończącą się na PID procesu ($$)? Otóż jeśli prometheusowy eksporter wstrzeliłby się w moment zapisu do pliku, mógłby odczytać uszkodzone metryki. Stąd na koniec atomowa operacja mv, która zapewnia integralność danych.
Powyższe tworzy trzy metryki, które będziemy mogli potem odczytać za pomocą pakietu prometheus_nodexporter - używają modułu textfile. Są to:
duplicati_$hostname_$path_last_run_startokreślająca ostatni czas startu skryptuduplicati_$hostname_$path_last_run_secondsprzechowująca czas wykonania w sekundachduplicati_$hostname_$path_last_exitcodezawierająca ostatni kod wyjścia skryptu
Kombinacja last_run_start oraz last_exitcode pozwoli kwerendzie Prometheusa ustalić, czy host spróbował zacząć backup w ustalonym okresie (np. 24h) oraz co mu z tego wyszło. last_run_secods może się przydać do późniejszej analizy statystyk czy coś nie wykonywało się za długo.
Sam Prometheus to ogromny temat, dlatego poruszę tu tylko dwa elementy w jednym z wielu możliwych setupów - node_exporter na monitorowanym boksie i sam prometheus na centralnym serwerze monitorującym. Ten drugi można poszerzyć o alertmanagera i integrację na przykład z PagerDuty.
Zacznijmy zatem od centralnego prometheusa. Potrzeba nam przynajmniej trzech plików konfiguracyjnych: /etc/default/prometheus zawierającego ogólne parametry takie jak IP serwera, /etc/prometheus/prometheus.yml definiującego interwały checków oraz źródła danych, czyli monitorowane hosty oraz przynajmniej jednego pliku z regułami alertów znajdującego się w /etc/prometheus/rules/.
Minimalna zawartość /etc/default/prometheus to ARGS="--web.listen-address=EXTERNAL_IP:9090". Zadeklarowanie adresu IP explicite jest ważne jeśli przypadkiem mamy włączoną obsługę IPv6 - golangowe biblioteki używane przez prometheusa upierają się na bindowanie do IPv6 przed IPv4, a sam prometheus binduje się tylko do pierwszego adresu.
Kolej na prometheus.yml. Potrzebujemy czegoś w rodzaju:
global:
evaluation_interval: 15s
scrape_interval: 15s
scrape_timeout: 10s
external_labels:
environment: prometheus
rule_files:
- /etc/prometheus/rules/*.rules
scrape_configs:
- job_name: 'MONITORED_HOST'
static_configs:
- targets: ['MONITORED_HOST_IP:9100']
- job_name: 'MONITORED_HOST2'
static_configs:
- targets: ['MONITORED_HOST2_IP:9100']
...
I na koniec plik z regułkami. Pozwolę sobie, zamiast konkretnej wartości, wskazać Jinjowy template, którego używam w Ansiblu by go wygerować:
---
groups:
- name: Amaterasu
rules:
{% for dj in duplicati_monitored_jobs %}
- alert: MONITORED DUPLICATI JOB {{dj.metric}} DIDNT START IN 24hrs
annotations:
message: '{{dj.metric}}'
description: 'todo: add last exec time here'
expr:
time()-duplicati_{{dj.metric}}_last_run_start>86400
or
absent(duplicati_{{dj.metric}}_last_run_start)
for: 1m
labels:
severity: error
- alert: MONITORED DUPLICATI JOB {{dj.metric}} HAD FAILURE
annotations:
message: '{{dj.metric}}'
description:
expr:
duplicati_{{dj.metric}}_last_exitcode>9
for: 1m
labels:
severity: error
{% endfor %}
Praktyczny foreach stworzy automatycznie dwa alerty na każdy monitorowany job duplicati - jeden sprawdzający, czy backup się uruchomił w ciągu ostatniej doby, a drugi czy exitcode oznacza sukces kopii zapasowej. Warto zwrócić uwagę na or absent(...) - pozwala to złapać także przypadki kiedy metryka w ogóle wyparowała z systemu - PromQL (czyli SQL używany przez Prometheusa) nie uznaje null jako wektora danych.
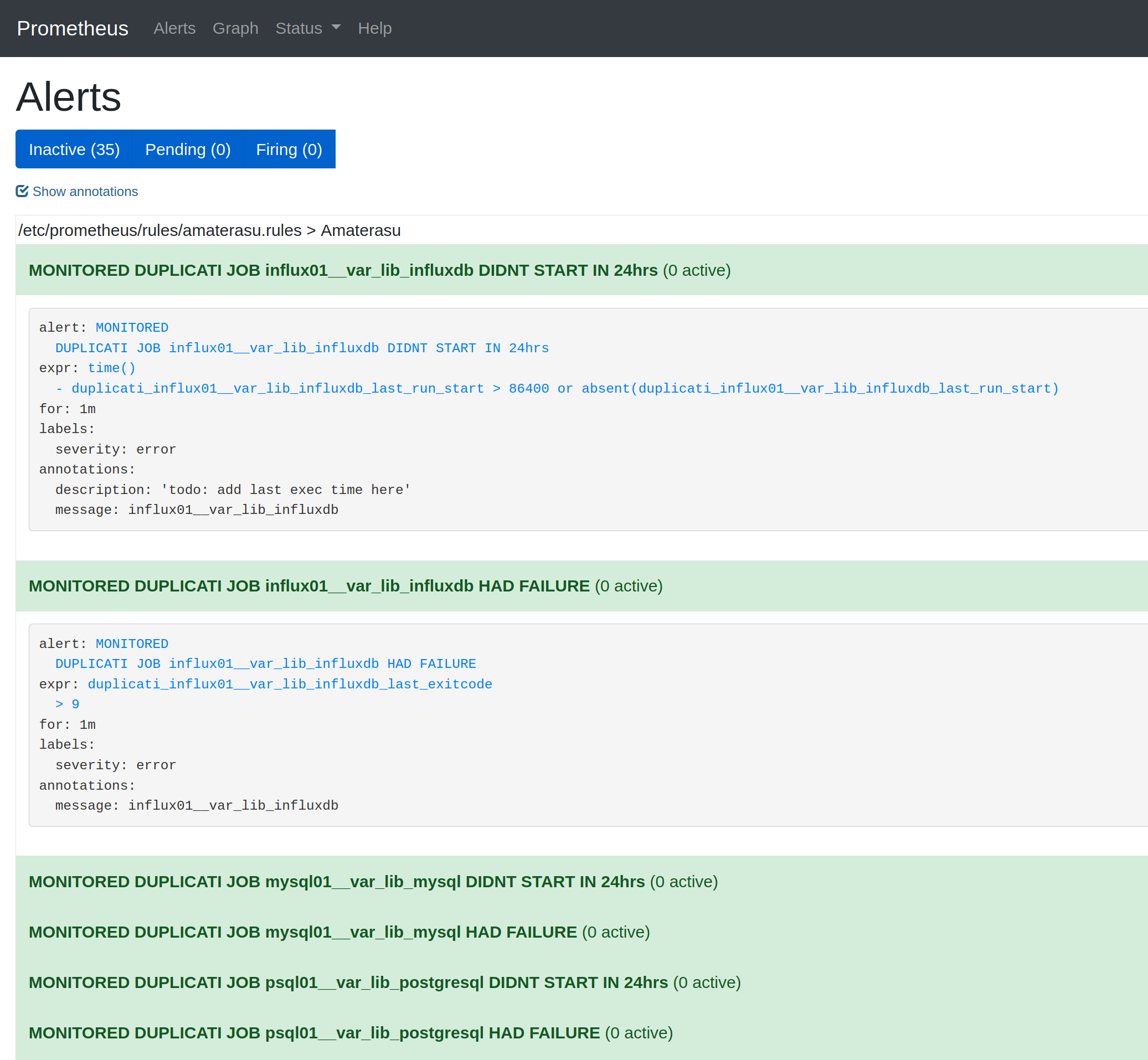
Natomiast przechowywana w ansiblowym host_vars tablica duplicati_monitored_jobs wyglądać może tak jak w poniższym wycinku. Godne uwagi jest to, że wartości pola metric są zgodne z wartością $metrics_name stworzoną we wrapperze.
---
duplicati_monitored_jobs:
- metric: influx01__var_lib_influxdb
- metric: psql01__var_lib_postgresql
- metric: mysql01__var_lib_mysql
Teraz warto zainstalować i skonfigurować prometheus_nodexporter na monitorowanych boksach. Paczka na większości systemów nazywa się tak jak binarka. Konfiguracja odbywa się poprzez plik /etc/default/prometheus. Na pewno musimy w nim zawrzeć przynajmniej ARGS="--web.listen-address=EXTERNAL_IP:9090 --collector.textfile.directory=/var/lib/prometheus/node-exporter". IP jest tu z tego samego powodu co w serwerze, zaś --collector.textfile.directory znany jest nam już jako $metrics_dir z wrappera.
Efekt naszych starań powinien przypominać coś takiego w Prometheusowym WebUI:
Deployment jobów #
Ostatnim krokiem jest zdeployowanie naszych jobów, czyli zasadniczo wpisów w crontab z wywołaniem skryptu wrappera. Poniżej ansiblowy playbook, który dodatkowo zajmie się zainstalowaniem dependencji.
---
- name: 'install duplicati'
apt:
deb: 'https://updates.duplicati.com/beta/duplicati_{{duplicati_ver}}_all.deb'
- name: 'install wrapper'
copy:
src: 'duplicati_wrapper.sh'
dest: '/opt/duplicati_wrapper.sh'
mode: 555
- name: 'set up schedules'
cron:
name: 'duplicati_{{item.path}}'
minute: '{{item.minute}}'
hour: '{{item.hour}}'
job: /opt/duplicati_wrapper.sh {{item.path}} {{duplicati_dropbox_authid}} {{duplicati_passphrase}} '{{item.retention}}'
with_items: '{{duplicati_jobs}}'
- name: 'make sure prometheus_nodexporter is set up - param'
lineinfile:
line: 'ARGS="$ARGS --collector.textfile.directory=/var/lib/prometheus/node-exporter"'
path: '/etc/default/prometheus'
- name: 'make sure prometheus_nodexporter is set up - dir'
file:
path: '/var/lib/prometheus/node-exporter'
state: directory
owner: prometheus
- name: 'make sure prometheus_nodexporter is set up - service'
systemd:
name: 'prometheus-node-exporter'
state: restarted
Żeby ten playbook działał potrzeba nam duplicati_wrapper.sh czyli skryptu wrappera, który napisaliśmy w dwóch poprzednich sekcjach oraz kilku zmiennych:
duplicati_ver- obecnie najnowsza to2.0.5.1-1duplicati_dropbox_authid- coś, co uzyskamy z https://duplicati-oauth-handler.appspot.com/duplicati_passphrase- hasło do szyfrowania AES256 - najlepiej, jeśli będzie ustawione na poziomie hostaduplicati_jobs- tablica z opisem jobów - musi być ustawiona per host, przykład poniżej
---
duplicati_jobs:
- path: /var/lib/influxdb/
retention: "1W:1D,4W:1W,12M:1M"
hour: 2
minute: 0
Całość najlepiej upakować do ansiblowej roli, którą można dodać do playbooka tworzącego maszyny lub osobnego deployującego nowe konfiguracje do wszystkich monitorowanych hostów.
Podsumowanie #
Duplicati jest bardzo przyjemnym w używaniu systemem backupów, a właściwie to nie systemem, a zestawem narzędzi, które backupy tworzą po stronie klienta. Daje to wygodę w doborze metody automatyzacji - w tym używaniu wbudowanego w narzędzie dla desktopów schedulera oraz miejsca docelowego z naciskiem na mnogość form backupu do chmury.
W artykule opisałem jak w szybki sposób zintegrować Duplicati na serwerach przy użyciu crontaba i prostego wrappera oraz monitorować stan używają Prometheusa.